

By Rebekah Morris for AZBEX

The saying “Garbage In, Garbage Out,” has been around a long time now. That sentiment applies as we explore how good or bad data will amplify your business operations, especially using AI.
AI has been promising powerful gains in efficiency, analysis and business outcomes since at least late 2024. Although A/E/C firms are notoriously slow to adopt new technology, we are seeing new applications pop up more and more in our industry.
From accounting to marketing & business development to operations, AI is either creeping in or exploding all around us. When planned and executed well, the results can be stunning, but these positive end results only come with a good strategy and data going in.
Recently, I’ve had several discussions on various AI-related topics, including Dave DuVarney, Principal of Baker Tilly, and Ali Fakih, CEO of AIAEC and Sustainability Engineering Group, to discuss how much the quality of data can impact the output of any AI tool and task, as well as the continued importance of actual human expertise.
Another resource I’ve been reading is a commentary by Jack Enfield with Computer Dimensions out of Tucson. His posts have a good balance of focusing on what actual people say, combined with local IT depth of knowledge (I can look past his writing style, which appears to be AI-generated).
Governance and Strategy Come First
AI governance means consistency of terminology: standards, common definitions and master data. Strong governance gives teams the best chance of communicating effectively about tasks and outcomes.
There is a common misconception about how much AI can actually do. Then, when we get in there and try it and it fails, we tend to give up on it.
While developing an AI strategy is well beyond the scope of this article, there are a few principles of AI implementation that are becoming apparent:
- Brainstorm what AI could be good at and compare against what potential time savings and/or quality improvements could be realized.
- The more context, the better. When we prompt any AI tool, we give it a role. We tell it who we are, what audience we are trying to work for, what output we are looking for, etc.
- Start with tasks where you can verify the output is what you would expect.
- Iterate repeatedly. As the model gets trained on what you want, results get better.
Clean Data is Needed
DuVarney explained how the quality of the underlying data is paramount. AI cannot just “magically clean up bad data,” he says. AI can spot anomalies, check for compliance and alert to potential errors, but a person still has to go back in, find and update missing or incomplete data, and iterate through the AI process again.
For those who have implemented AI processes and are now realizing the underlying data is leading to poor results, DuVarney says the only right path is to fix the underlying raw data. This mirrors a series of recent blog posts by Enfield, who similarly harped on the importance of doing the hard, tedious and time-consuming work of building pristine data sources first, then applying AI to answer the business question at hand.
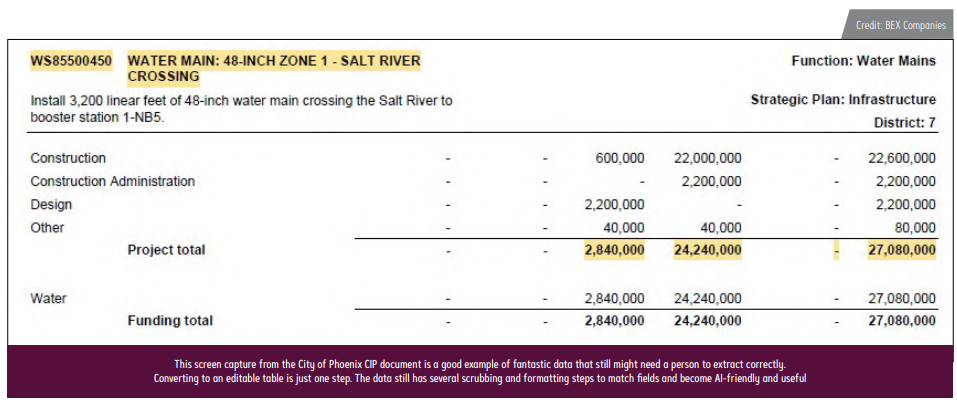
Use Case: CIP Data
A relevant local example is Capital Improvement Plan data. We do this research every year and, on the surface, it should be a fantastic use case for AI. At its core, CIP data is publicly available government documents that are all required by state statute to include the same information. AI eats long, complex documents for breakfast.
In practice, however, there is significant variation in the documents that must be accounted for first. This requires the time-consuming step of structuring the relevant data and checking for accuracy before applying the AI tool. In fact, we still find CIP documents that are scanned and uploaded or formatted ways that we cannot convert to tables at all.
Not to be overly self-promoting, but that’s where having an outside data source like BEX comes in handy, since one of our major tasks every year is taking the time to source all the documents and clean up the data.
Use Case: Purpose-Built AI for Property Due Diligence
Ali Fakih with SEG has spent decades preparing rezoning cases across Arizona and beyond. He has applied that institutional knowledge into a custom-built AI called ChatAEC. When speaking with Fakih, I asked why I couldn’t just ask ChatGPT to do what his custom GPT did. His answer also came back to the data.
The expertise gained from decades of doing the work enabled him and his team to build the right tool to solve a down-to-the-ground business problem. The model is trained to source accurate information and take it further by producing a standardized report that can then be used by developers and land use attorneys to either build a rezoning case or perform due diligence on a parcel. If someone without that institutional knowledge were to attempt to produce the same tool, we wouldn’t know if the output was bad.
Human Expertise Still Required
In both of these use cases, a human is still required. AI is not good enough to fill in gaps of missing data or to train and craft an agent to do the work.
DuVarney recounted a lesson from earlier in his career when he made a mistake. His boss came over to him and succinctly stated, “If you give me bad data, I make bad decisions.” In a world where business decisions affect multi-million-dollar projects, good data is worth investing in.
